

 摘要:
在数字化时代,音频内容的传播已经变得越来越普遍,然而有时我们可能需要将音频文件转化为文字,以便更好地进行分析、编辑或共享。尽管市面上有许多付费工具提供音频转文字的服务,但是我们也可...
摘要:
在数字化时代,音频内容的传播已经变得越来越普遍,然而有时我们可能需要将音频文件转化为文字,以便更好地进行分析、编辑或共享。尽管市面上有许多付费工具提供音频转文字的服务,但是我们也可... 在数字化时代,音频内容的传播已经变得越来越普遍,然而有时我们可能需要将音频文件转化为文字,以便更好地进行分析、编辑或共享。尽管市面上有许多付费工具提供音频转文字的服务,但是我们也可以利用一些免费的方法来实现这个目标。本文将为您介绍一些高效、准确且免费的音频转文字方法。

一:优质在线工具之Google语音识别
Google语音识别是一款强大而准确的在线工具,可以将音频文件转化为文字。它基于机器学习和人工智能技术,能够识别多种语言,并且具有高度的准确率。用户只需上传音频文件,稍等片刻,就能够得到转化后的文字文本。
二:智能手机应用之iTranscribe
iTranscribe是一款功能强大的智能手机应用程序,可以将录音转换为文字。用户只需将录音文件上传到应用程序中,iTranscribe便会自动将其转化为文字,并提供编辑和导出功能,方便用户进行后续处理。
三:利用在线转换网站进行音频转文字
除了Google语音识别之外,还有许多在线转换网站可以免费将音频转化为文字。这些网站通常提供简单易用的界面,用户只需上传音频文件,然后选择转换选项,即可获得转化后的文字文本。一些常用的在线转换网站包括Zamzar、OnlineAudioConverter等。
四:免费语音识别软件之Audacity
Audacity是一款免费的开源音频编辑软件,除了具有强大的音频处理功能外,它还提供了语音识别功能。用户只需将音频文件导入Audacity中,然后使用语音识别插件,即可将音频转化为文字。
五:利用YouTube自动字幕生成功能
YouTube是全球最大的视频分享平台,它提供了自动字幕生成功能,可以将视频中的语音自动生成字幕。用户只需将音频文件制作成视频并上传到YouTube上,然后等待一段时间,便可以获得自动生成的字幕文件,从而实现音频转文字的目的。
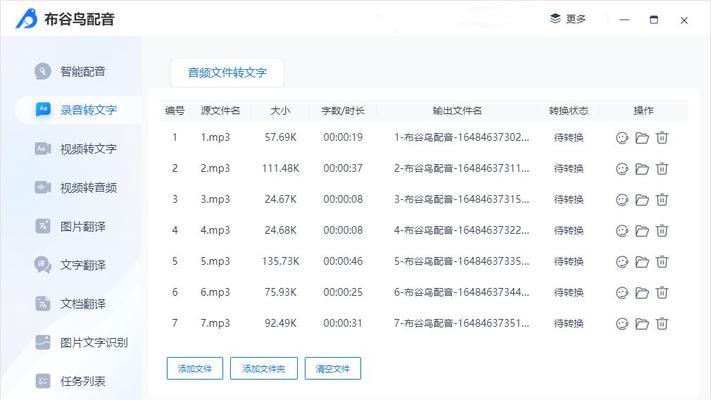
六:基于开源技术的音频转文字工具之CMUSphinx
CMUSphinx是一款基于开源技术的音频转文字工具,它提供了一系列的语音识别功能,支持多种语言。用户可以通过使用CMUSphinx的API或者本地安装程序,将音频文件快速转化为文字。
七:云端智能助手之百度语音识别
百度语音识别是一款强大的云端智能助手,可以将音频转化为文字。它具有较高的准确率和稳定性,并且支持多种语言。用户只需将音频文件上传到百度语音识别平台,然后稍等片刻,便可得到转化后的文字文本。
八:利用Python语音识别库进行音频转文字
Python是一种流行的编程语言,在其生态系统中有许多语音识别库可供使用。例如,SpeechRecognition是一款优秀的Python库,它支持多种语音识别引擎,并且提供了简单易用的API,用户可以利用该库实现音频转文字的功能。
九:微软Azure认知服务之语音转文本
微软Azure认知服务提供了强大的语音转文本功能,可以将音频文件转化为可编辑的文本。用户只需在Azure认知服务平台上创建一个语音转文本资源,然后上传音频文件,稍等片刻,便可得到转化后的文字文本。
十:免费开源项目之DeepSpeech
DeepSpeech是一个免费开源的语音识别引擎,由Mozilla开发。它基于深度学习技术,可以将音频转化为准确的文字文本。用户可以通过使用DeepSpeech的API或者本地安装程序,实现高效的音频转文字功能。
十一:使用在线文字转语音工具验证转换结果
为了验证音频转文字的准确性,用户可以使用在线文字转语音工具,将转换后的文字文本转化为语音播放。通过听取转换结果的语音,可以快速检查和修正任何转换错误。
十二:注意保护隐私信息
在进行音频转文字的过程中,用户需要注意保护个人隐私信息。尽量避免将包含敏感信息的音频文件上传到不可信的平台或工具上,以免造成信息泄露。
十三:了解语音识别引擎的限制
不同的语音识别引擎在识别准确度、支持语种和文件格式等方面可能存在差异。用户在选择音频转文字工具时,应该了解其限制,并根据自己的需求进行选择。
十四:定期校对转换结果
即使使用了高效、准确的音频转文字工具,也可能会存在一定的转换错误。用户应该定期校对转换结果,确保文字文本的准确性。
十五:
通过本文介绍的免费音频转文字方法,用户可以快速、准确地将音频文件转化为文字,从而更方便地进行编辑、分析和共享。无论是在线工具、智能手机应用还是开源技术,都可以满足不同用户的需求。然而,在使用这些工具时,用户需要注意保护个人隐私信息,并了解语音识别引擎的限制。只有正确使用这些方法,才能获得高效、准确的音频转文字结果。